I have been working with Terraform again recently and one of the things that I have to deal with on a regular basis is making sure that resources are named appropriately. When I say appropriately I mean that they all follow the same standard pattern, with prefixes etc. My default is to go for the suggested structure from the Microsoft Cloud Adoption Framework (CAF) documentation. Unless you have a custom resource naming convention already this is a really good place to start. Additionally, they provide a useful list of resources and prefixes for them to use as a reference too.
It is all well and good having these conventions, but remembering to apply them to each resource definition can be arduous as teams scale. While it can be caught with test automation and code reviews it would be nice not to let them get that far. If we are using Terraform then we can make use of some of the features built in to perform string manipulation as well as encapsulating the complexity into lookups which the team can use.
Over time my technique has evolved from defining them in-line to locals, the most recent iteration of my preferred method came about after working with Hamish Watson (linkedIn | blog) on a couple of little projects and seeing the way that he was working. So, thanks Hamish for helping me continue to evolve my approach, I’ll buy you a beer next time we catch up mate.
Resources
All of the resources associated with the blog post can be found here.
Terraform Local values
Terraform local values (aka locals) allow us to encapsulate expressions and value assignments into a central location within our Terraform projects. This then allows us to reference the local value in our resource definitions. This gives us the ability to then make a central change which will be replicated out to all of the places which we call it, small change for big results. This also has the added benefit that we can assign an input variable to a locals to provide a level of abstraction from the way we use those inputs within our projects, again aiding in maintainability.
Locals can be declared with multiple sub-elements to them so we can logically group related expressions or values to be referenced later. This includes the ability to define the various different type constructors from scalar values through to collection types including lists, maps, sets, etc. Where the locals differ from variables is that we can take an output from a resource declaration and use that as part of a locals definition so that they can be more dynamic in nature.
Hopefully this has given you a taste of what is possible with locals and why they form the basis of the resource naming automation process I use to help with my Terraform project creation.
Using Locals to Drive Naming Automation
There are a couple of stages that we will go through to create a functional terraform project which we will cover here.
Project Setup
When setting up a Terraform project I like to decompose it down into multiple files within the project directory. I find this works well for me by making it a bit more modular as well as minimising complexity of code maintenance for code changes and other similar activities. The general structure which I use is as follows.
- providers.tf
- variables.tf
- outputs.tf
- naming.tf
- main.tf
We will be focused in the variables and naming files today, with a bit of work in main when we actually use the locals calls to define resource name attributes.
Defining the Variables
Based on the base CAF naming structure we will need to accept some inputs for properties which will be used for our resource names. Here we will use a set of variables to take the inputs, the definition of which can be seen below.
1variable "applicationName" {
2 type = string
3 description = "Please provide the workload or application name descriptor for resources to be deployed."
4}
5variable "environment" {
6 type = string
7 description = "Please provide the environment descriptor for the resources to be deployed. Valid options are dev, test, stage, prod."
8
9 validation {
10 condition = contains(["dev", "test", "stage", "prod"], lower(var.environment))
11 error_message = "Incorrect value passed for environment name, valid options are dev, test, stage, prod."
12 }
13}
14variable "azureRegion" {
15 type = string
16 description = "Please provide the Azure Region for the resource deployment."
17}
18variable "applicationInstance" {
19 type = string
20 description = "Please provide the instance ID for the workload or application deployment."
21}One thing that you will also notice here is that I am performing some basic input validation on the environment variable. This is because the values here are normally prescriptive and limited to a small set of options. In my view, and experience, it makes sense here to try and push any issues back to the user as early in the process as possible with a descriptive message to help prevent issues down the line. I’m also a fan of explicitly casing the input to perform the checks to try and avoid any issues when performing equality checks. Now we have these we can progress to defining the locals, having the variables pre-defined means that we can leverage the intellisense in tools like VSCode (which is my tool of choice here).
Defining the Naming Locals
We will be defining two locals blocks in to achieve our outcome. The first of these is the one which will build up the bulk of the object names which we will be applying to the resources that we deploy.
The first item in the locals is for what I term the baseName which is the default of a hyphen separated name structure which aligns with the main CAF structure. The join string function within Terraform allows us to take a list of inputs and concatenate them separated by a specified separator string. Here we specify the “-” separator to use and then provide the variables in the correct order in list format. Here is also where I set the casing of the name structure, personal preference for resources is lower case. The reason for this is that there are certain resources which need to be deployed with a lowercase name (looking at you storage accounts…) and I like consistency. However, if you want something different there are also functions for upper and titlecase available.
The safeName is the baseName with the hyphens removed so that it is able to be used for storage accounts and others where there are similar restrictions.
Finally, underscoredName comes from my history working as as DBA and liking my databases to have underscores in the name rather than hyphens if there is a need for a symbolic separator. Mainly because it saves with issues in maintenance scripts and tooling which do not like the hyphens. An alternative is to just simply use the safeName but I find the separated name easier to read.
1# Naming structure according to CAF
2## <Resource Type>-<Worklaod/App>-<Environment>-<Azure Region>-<Instance>
3## Resouce type will be added via lookup at the resource.
4locals {
5
6 baseName = lower(join("-", [var.applicationName, var.environment, var.azureRegion, var.applicationInstance]))
7 # Certain resourecs like storage accounts need lowercase with no non-alphanumerics.
8 safeName = replace(local.baseName, "-", "")
9 # Some things like sql databases work better in other tools with underscores rather than hyphens.
10 underscoredName = replace(local.baseName, "-", "_")
11}There is one name option which I also use sometimes but have not included here. It is the what I call uniqueName which injects a random hex string into the name structure at a specific point. This can be useful for things which reside in a scope which requires a globally unique name such as storage accounts. There are other ways to achieve it by including the organisaiton name which is another suggestion in the CAF. I’ll leave it up to you if you feel the need to go down that route.
One thing that you will see is missing from the naming structure is the resource type prefix. Because this is resource specific we cannot easily build it into this name constructor. Instead we will select the appropriate one at resource definition. But first we need to setup another local which will contain a map of our prefixes by resource type. You can see the way I have done this below.
1# Contains all constants for resource naming for this Terraform solution
2# See: https://docs.microsoft.com/en-us/azure/cloud-adoption-framework/ready/azure-best-practices/resource-abbreviations
3locals {
4 azPrefix = {
5 resource_group = "rg"
6 azure_sql_database_server = "sql"
7 azure_sql_database = "sqldb"
8 storage_account = "st"
9 }
10}Here we are creating a map called azPrefix which then contains a set of keys and their corresponding values. This means that we will be able to lookup a specific resource prefix as we need when defining resources.
Putting it All Together
Now that we have the variables and the locals in place we can start defining our resources.
Starting with the resource group we define the azurerm_resource_group, when we set the name attribute this is where we will use the join expression again. We will provide the hyphen as the separator value. Then we will create the list of things to join by specifying the local value we want to retrieve, in this case it is the local.azPrefix.resource_group, followed by the local for the baseName. I am not using a lower() here because we have control over the casing of the prefix value in the local we define. If we did not have control of that then I would think about forcing case here if needed.
1resource "azurerm_resource_group" "rg-base-resourceGroup" {
2 name = join("-", [local.azPrefix.resource_group, local.baseName])
3 location = var.azureRegion
4}While this can look a bit arduous, because we have defined these local blocks we are able to leverage intellisense in our development workflow so we don’t have to remember what they are called. Rather we know that we are defining an Azure SQL Server so all we need to know is that we are calling the local.azPrefix map then let the tools to the rest,this can be seen in the figure below.
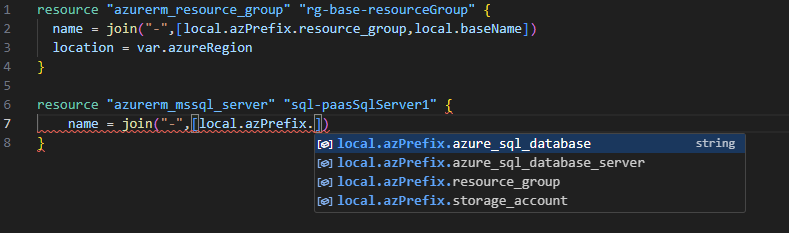
Now we can just finish off the creation of the other resources in our little cloud platform demo here, in the case of the Azure SQL Database and Storage Account we just use the underscore and lowercase names. The rest of the attribute values are assigned via standard variable assignments which can been seen below.
1resource "azurerm_mssql_server" "sql-paasSqlServer1" {
2 name = join("-", [local.azPrefix.azure_sql_database_server, local.baseName])
3 resource_group_name = azurerm_resource_group.rg-base-resourceGroup.name
4 location = azurerm_resource_group.rg-base-resourceGroup.location
5 version = var.azureSqlServerVersion
6 azuread_administrator {
7 login_username = var.sqlServerAdminEntraIdName
8 object_id = var.sqlServerAdminEntraIdObjectId
9 azuread_authentication_only = true
10 }
11}
12
13resource "azurerm_mssql_database" "sqldb-appdb1" {
14 name = join("_", [local.azPrefix.azure_sql_database, local.underscoredName])
15 server_id = azurerm_mssql_server.sql-paasSqlServer1.id
16 max_size_gb = var.azureSqlDbMaxSizeGb
17 sku_name = var.azureSqlDbSkuName
18 zone_redundant = var.azureSqlDbZoneRedundancy
19}
20
21resource "azurerm_storage_account" "st-blobstore1" {
22 name = join("", [local.azPrefix.storage_account, local.safeName])
23 resource_group_name = azurerm_resource_group.rg-base-resourceGroup.name
24 location = azurerm_resource_group.rg-base-resourceGroup.location
25 account_tier = var.blobstore1AccountTier
26 account_replication_type = var.blobstore1AccountRepType
27}Now we can deploy this using the normal plan and apply workflow to make sure that we are happy with what is going to be deployed.
1Terraform apply --var-file="./tfvars/demo.tfvars"If we use the Terraform Graph command with the Type=Plan switch then we can see where the locals sit in regards to the processing of the resource definitions and the resources which call them. We can see how the multiple calls are centralised so that if we make a change in one place that will cascade out to downstream resources.
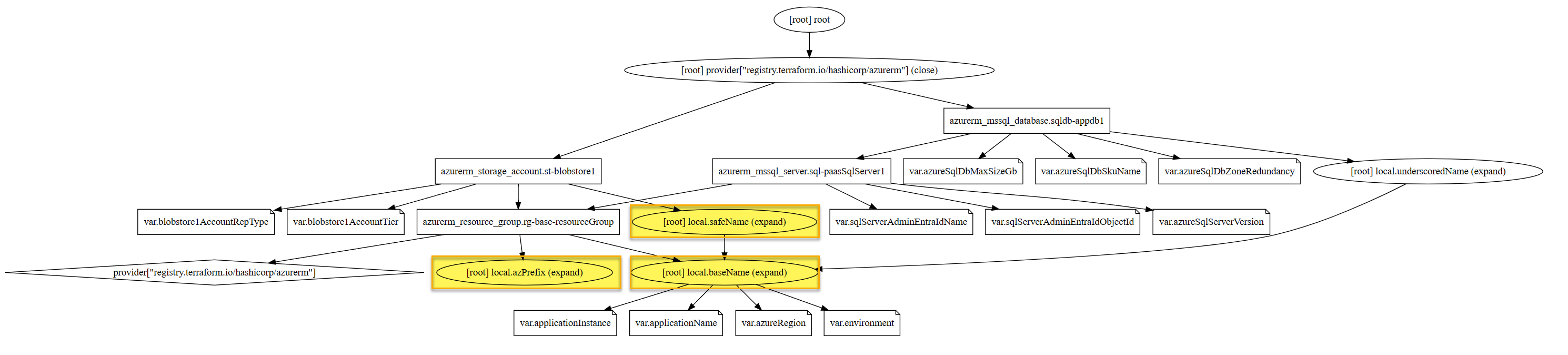
Summary
Hopefully this has helped demonstrate how it can make things a bit easier to standardise the naming resources within our Terraform projects when it comes to naming our resources. I have a template project directory which I pull down when I want to build anything out and having it in a central location again makes standarisation easier by making it easy to share with colleagues.
It would be great to hear if you have any variations or tips and tricks like this that makes standarisation easier for you and your team when it comes to defining and managing your Infrastructure as Code.
Thanks for taking the time to read.
/JQ
comments powered by Disqus