Another post from the T-SQL Tuesday archives finds me thinking about disaster recovery and how far things have come. Back in June of 2011 Allan Kinsel talked about how the onset of hurricane season inspired the topic. All the way back then I was in my first proper DBA role and managing an environment which was split between the south of the UK and also had two co-location sites in the US. We had an active site in Houston and and a DR site in Dallas, it was SQL Server 2000 configured with Log Shipping and a 20mb link between them.
Reinstating Log Shipping via UPS
While managing this particular configuration there was an issue on the secondary site which resulted in needing to reinstate log shipping on the secondary server. Ordinarily this would be a relatively normal task, backup the database, move it over, restore, then deal with the logs and get it all tied together. However, there was a small issue with the plan which was the combination of a 700GB database, not great storage, and a site to site link with limited bandwidth.
Working with a colleague we worked out that by the time we had managed to get all of the different moving parts lined up that we would be looking at having no DR capability for about three weeks if we used the network link. So, we had to think laterally, this is where a USB disk and UPS came into the mix. We worked out that even with a good old USB 1.0 device we would be able to get the DR environment back online in approximately week by shipping devices.
So, we ordered the device and got it sent to the facility and one of the techs on-site plugged it in for us. Now we started the database backup and waited. Luckily we had a third party backup tool which compressed the backup file down to a manageable size which meant that it would not take forever to transfer onto the USB drive from the SAN attached storage after the backup. From what I recall the process took about a day. Then we had the USB drive packed up and shipped same-day from Houston to Dallas where we got a tech to plug the drive in there so we could start the process of transferring to the SAN.
In the meantime we had started the process of taking and shipping log backups from the primary site to the secondary site This way the log backups were staged ready for us to start the restore process once the database was restored. We were not using the normal log shipping process here, rather one of my colleagues in the past had made some changes to use zip to compress the log backups before sending them over the wire which made life a lot easier.
Once we had manually restored the database backup, and the staged log files we turned the automated process back on and we were up and running again within the week. The USB drive stayed there just in case we needed it again, and luckily we did not need to use that while I was there.
How Have Things Changed?
Jumping forward a decade and I am managing an environment where we can use modern SAN hardware to shift terabytes of data between datacenters. Not only with improved synchronisation tech from the likes of Pure Storage, but also having significantly increased bandwidth for lower costs. The networking technology has moved on significantly in the time and largely kept pace with operational data volumes. Perhaps not the case with analytics workloads where it is not uncommon to have multi-terabyte and petabyte lakes and warehouses, but on the whole it is a lot more manageable.
If we look at the capabilities provided by cloud vendors today this has been greatly simplified.
If we look at Azure SQL Database, there are built-in capabilities which can be turned on to enable geo-redundancy. There are two different options, active geo-replication for protection at a database level, and failover groups which can be used to protect one or more databases on a logical server with automatic failover.
Additionally, when setting up our Azure SQL Database geo-redundancy for backups is a simple radio button selection. This then gives us the ability to perform a restore of one of our databases in another region in the event of the primary region having an outage.
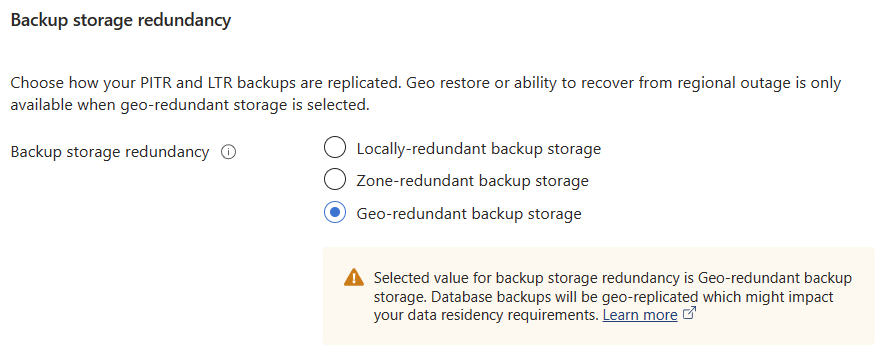
What was something that took a lot of effort to design, implement, and manage, is now an option we can enable. The cost benefit analysis of enabling these features has become a lot easier to justify because the overhead of a full infrastructure sat there which might be used has been replaced by an opex expense which can be calculated relatively easily. I have to say that managing data platforms today, this is not a headache I miss. Having the options available to me so that I can pick and choose what I need from the toolbox is nice. It lets me really concentrate on adding value by improving productivity, optimising processes, tuning workloads, and giving me time to learn new things.
How have things remained the same?
Even with all of the improvements in technology options for moving a lot of data there is still a need for putting data on a physical device and shipping it. Again, this is something that the cloud vendors offer. Microsoft Azure has the Data Box service, and AWS have the Snow Family. Both of which are mechanisms whereby you put data on a secure data device and ship it from one location to another. These are great when we have multiple terabytes of data or more to move to, or from the cloud.
Microsoft suggest that Data Box is good for 40TB+ data volumes, which is great if you are doing a bulk migration of data. One of the things I like about Microsoft’s offering is that they also highlight that it can be used to get data out of the cloud. In my time working with customers who have migrated to cloud, many have had concerns around the potential costs and timescales of repatriation or migration from the cloud. In reality I have not worked with anyone who has repatriated workloads from the cloud, migrated between cloud vendors yes, but not repatriated.
Where are things going?
I have to say that I don’t think that we will see any significant changes in the next decade in this area for large volume data transfer. Even with the improvements in network technologies and providers I think that there will still be a need to put data on a device and ship it between locations. The only thing that I think we will see is the diminishing volume of data on-premises for the majority of organisations. While there will always remain some who need to retain data on-premises for performance or security reasons, most will move to SaaS or PaaS options.
With more businesses using SaaS applications for business functions and then ingesting into cloud based analytics solutions based on data lakes & lakehouses like Microsoft Fabric or Databricks, there will be less data on our own kit. Again, I am happy to see this change from an operational standpoint, I would much rather spend my time working out how to get the most out of their data and applications for my customers to help them succeed than managing disks and storage.
It would be great to hear your experiences and thoughts around DR and how you think it has changed over the years and where you see it going.
/JQ
-
Previous
Tales from the T-SQL Tuesday Archive: #004 IO -
Next
Deploying Azure SQL Database with Terraform